
Explorer la médiation scientifique
-
CompaSciences est un moteur de recherche qui permet d’explorer les interventions d’universitaires sur la RTS.
-
CompaSciences permet d’identifier rapidement des experts et d’explorer les archives de la RTS de manière inédite.
-
À partir d’un corpus et de métadonnées, CompaSciences permet d’explorer dynamiquement les relations entre ce qui est exprimé (vocabulaire, notions…) et le contexte de cette expression (auteur, discipline, émission, genre…).
-
Ce projet a été financé par l’Initiative for Media Innovation (IMI), en partenariat avec Avis d’experts (AdE) et les archives de la RTS.
Recherche
La barre de recherche permet de chercher par terme, émission, expert·e, institution, genre et domaine.
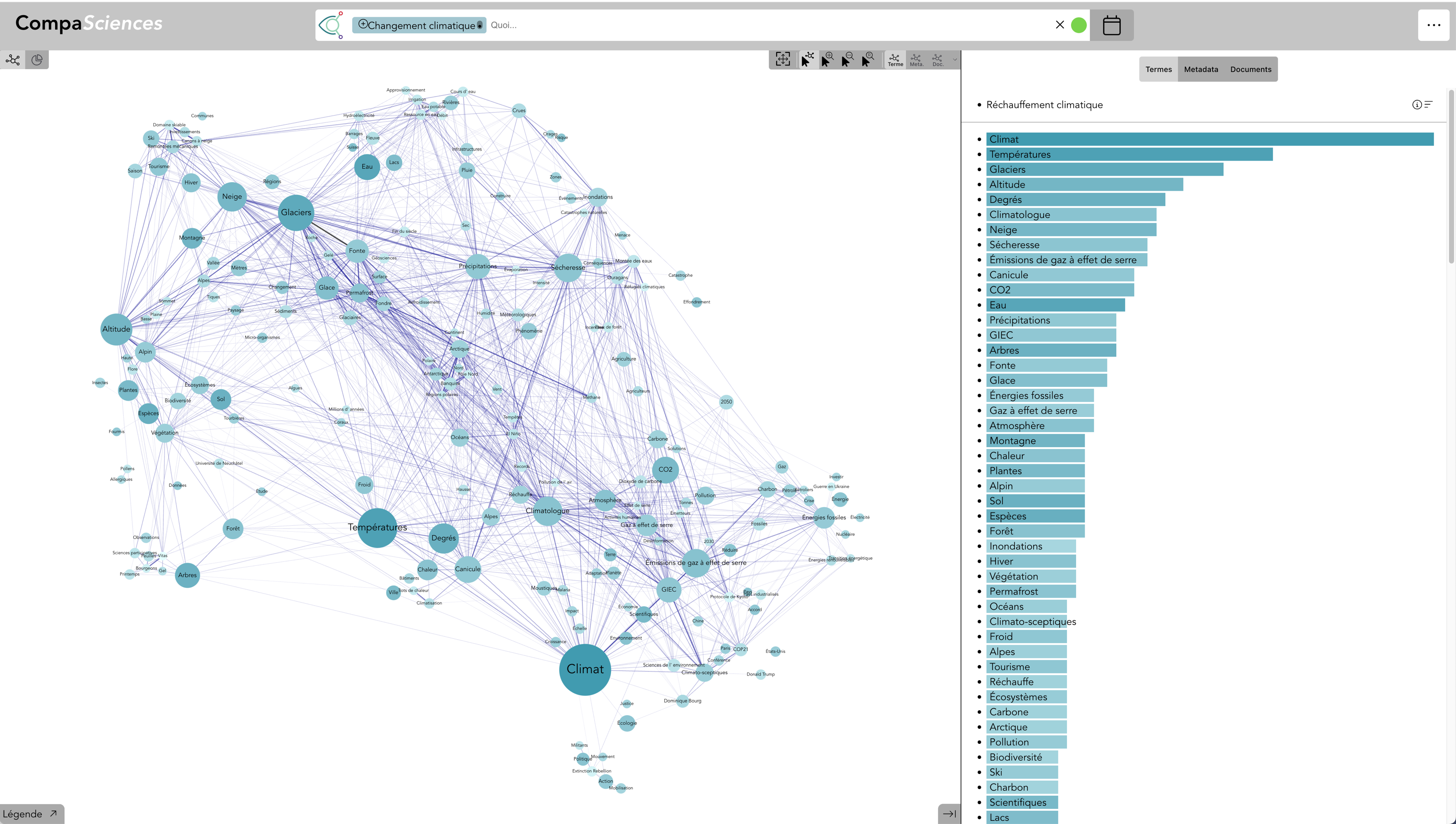
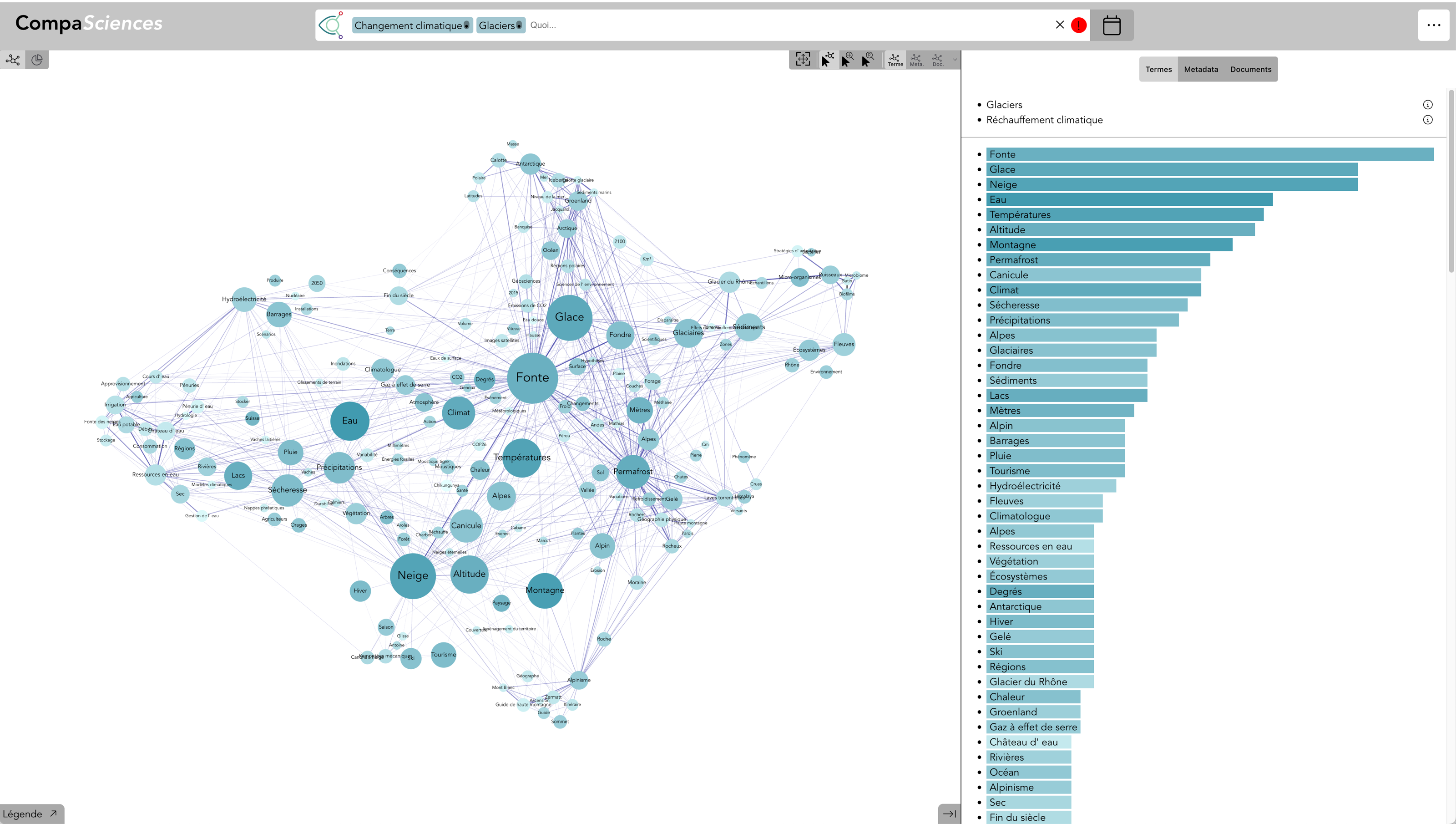
Exemples sur la durabilité
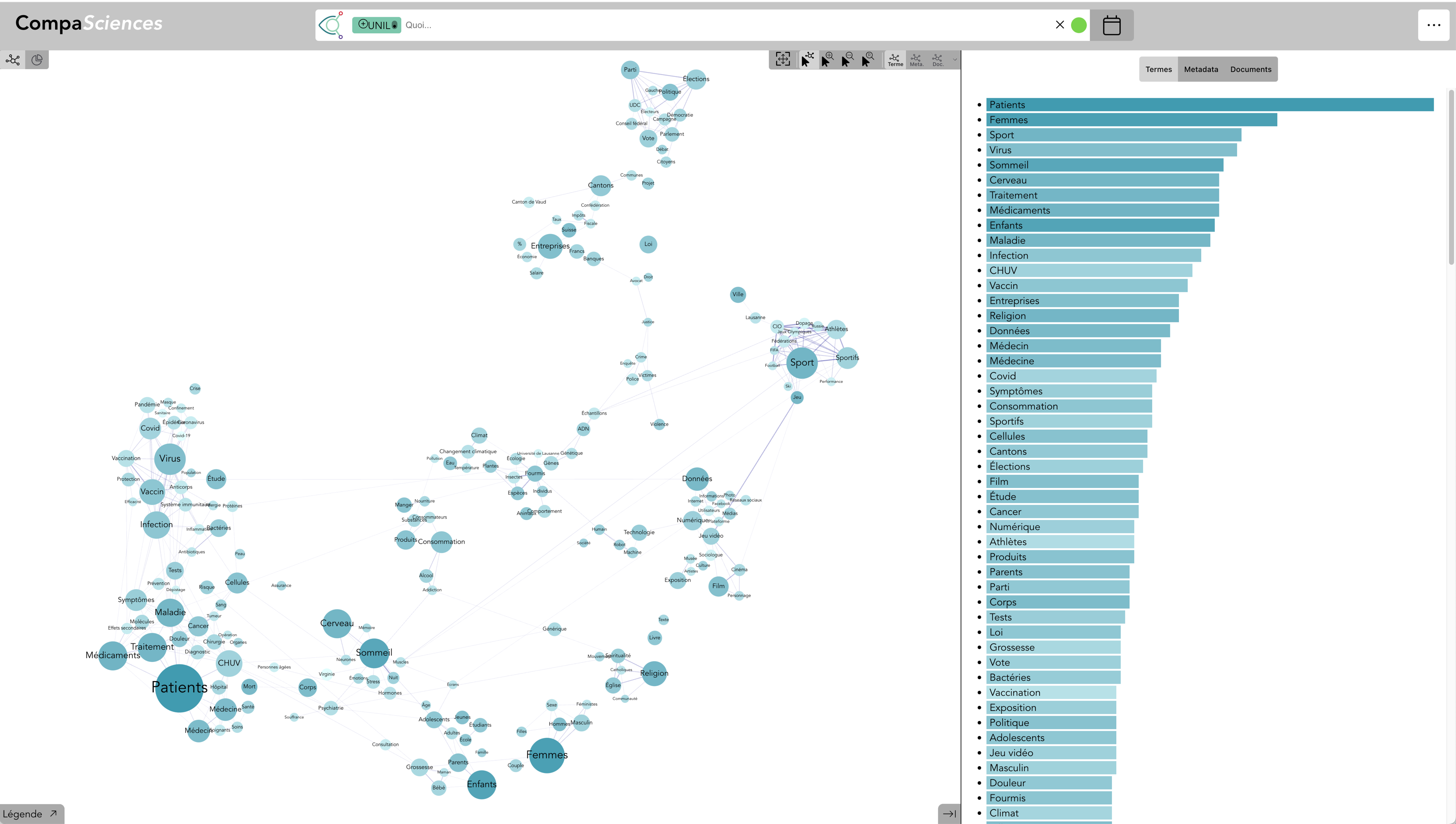
Termes : Durabilité (live)
Le terme durabilité est automatiquement associé au champ sémantique de « durable »
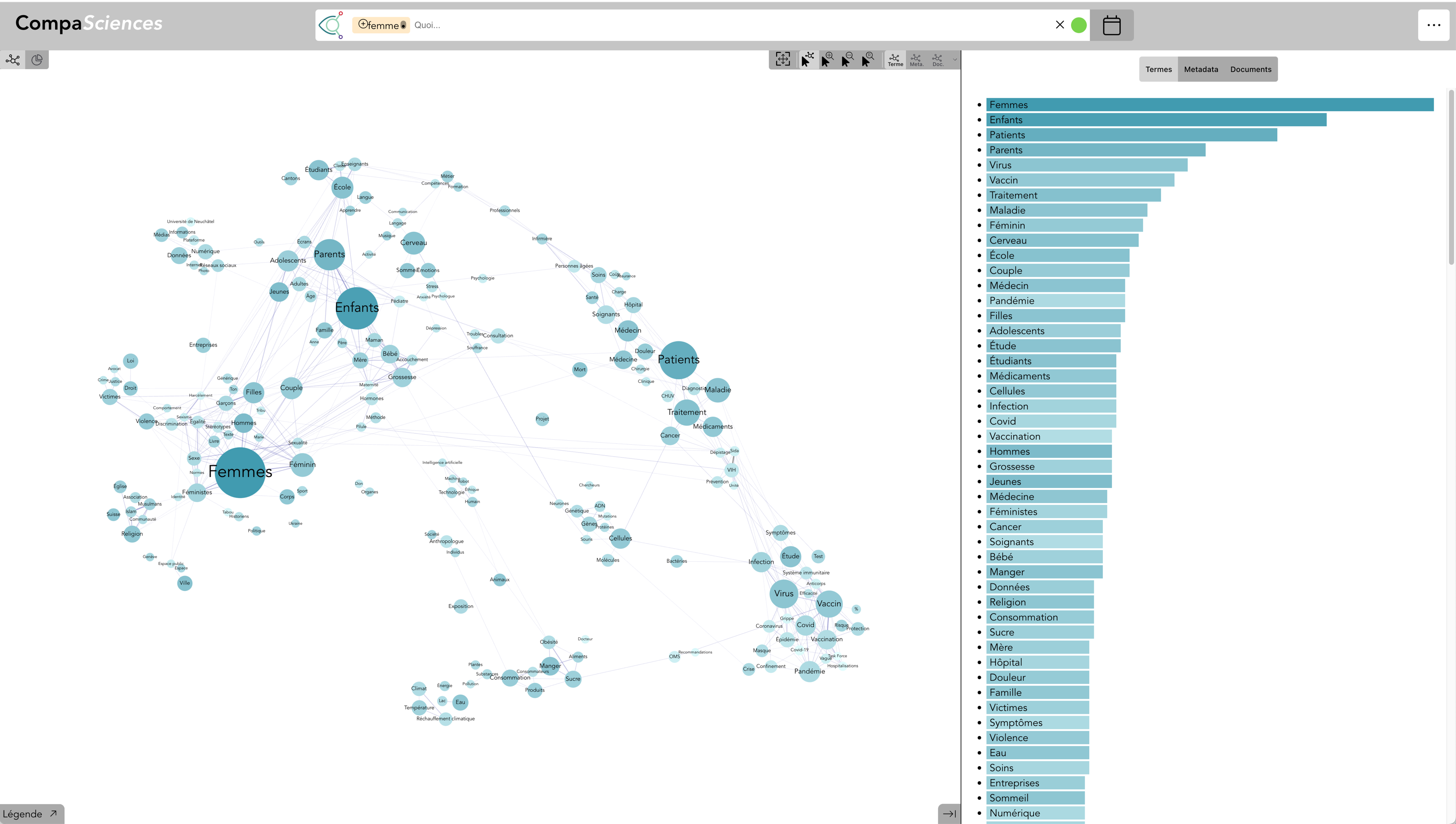
Termes : Durabilité - avec Expert·e·s (live)
Il est possible de spatialiser les expert·e·s selon leur spécialité
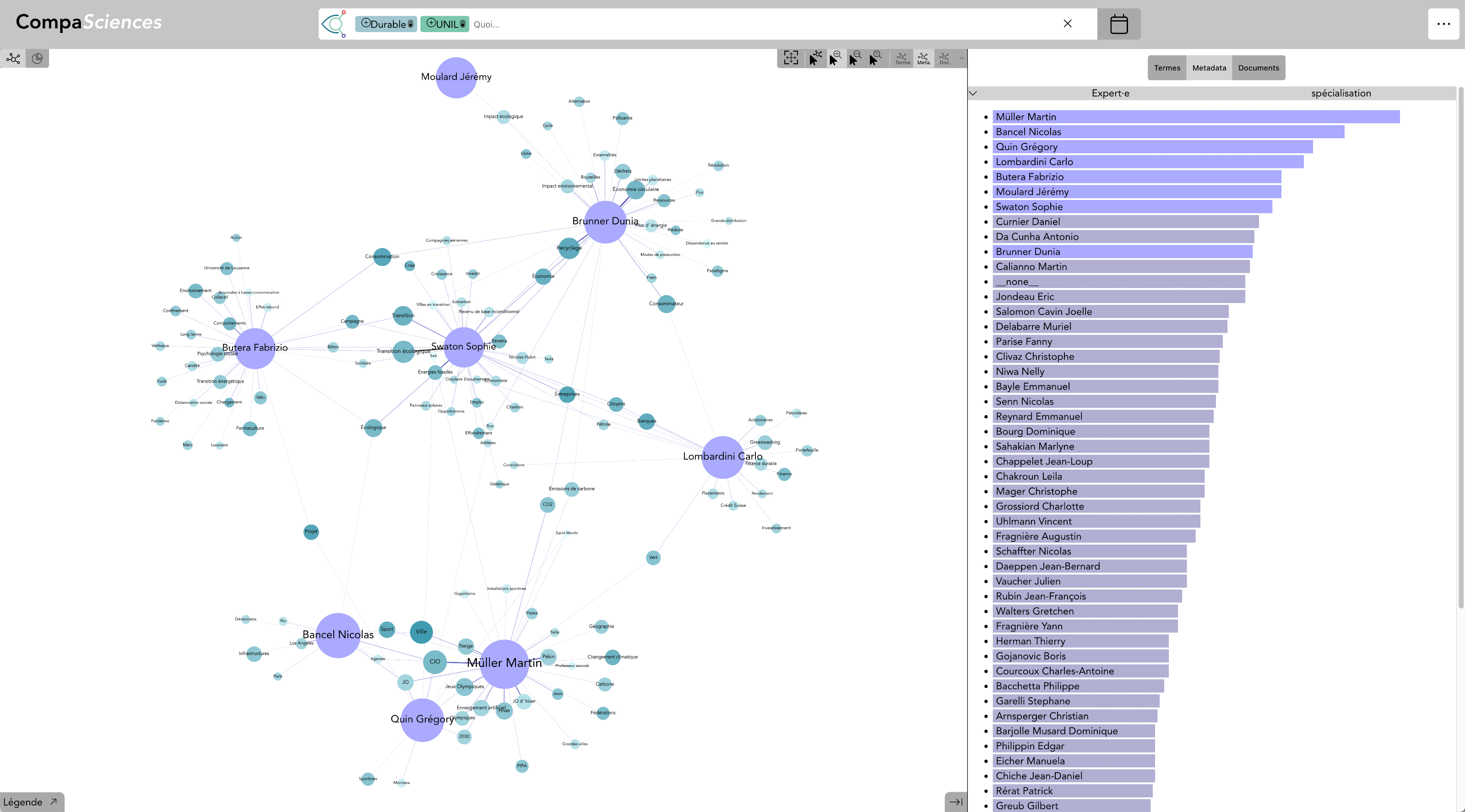
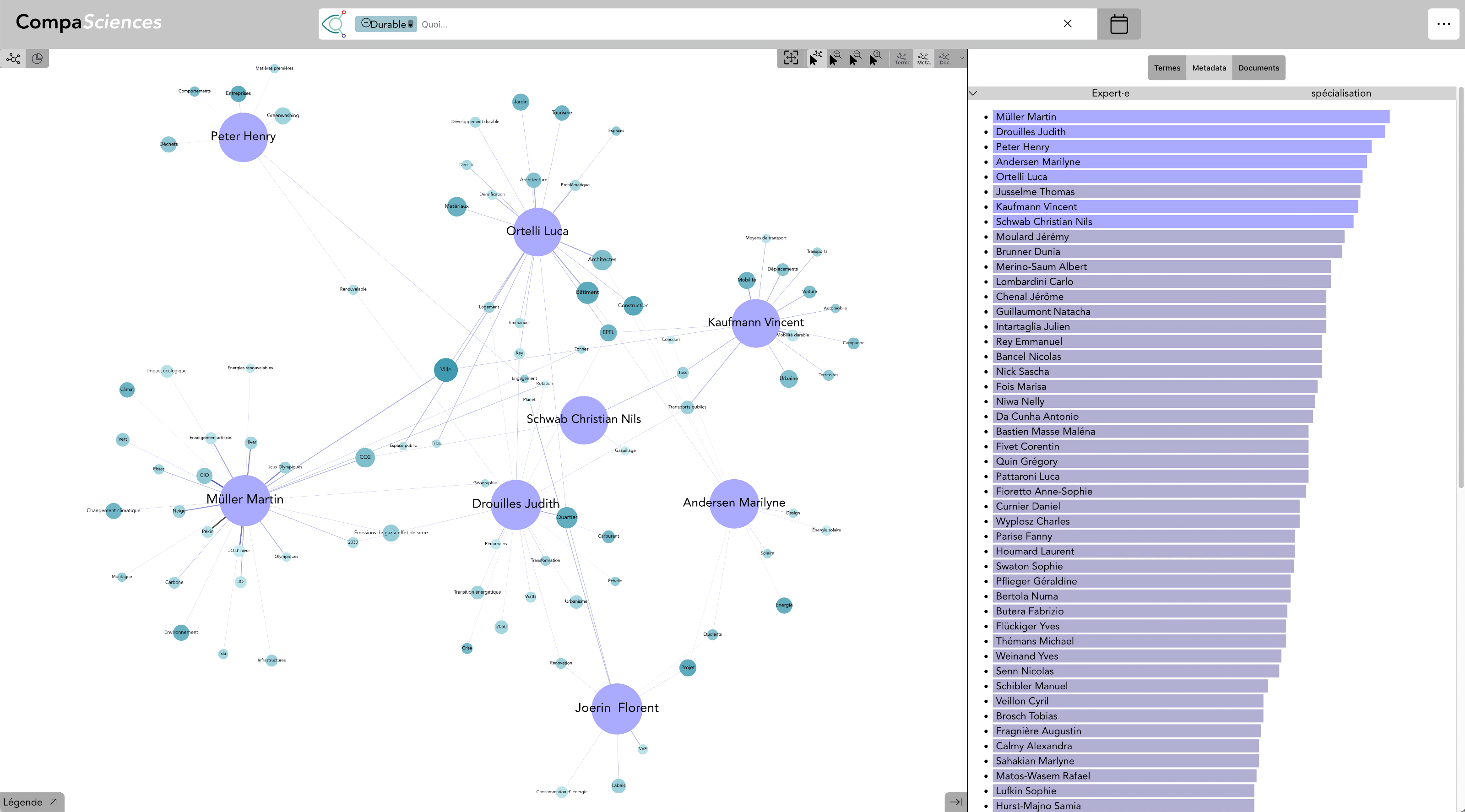
Terme : Durabilité & Institution : UNIL - avec Expert·e·s (live)
En ajouter l’institution UNIL à la recherche, seul·e·s les expert·e·s de l’UNIL sont représenté·e·s
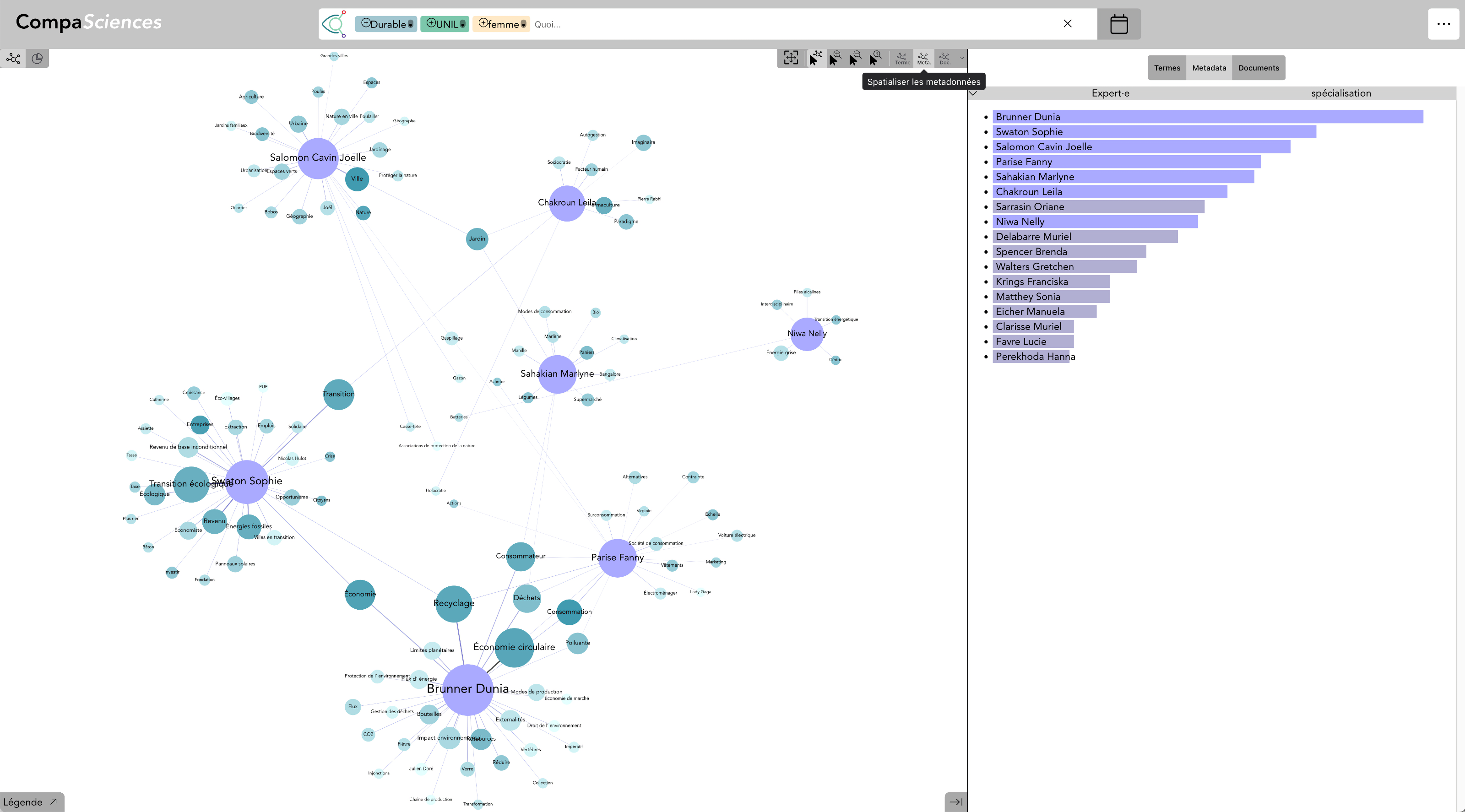
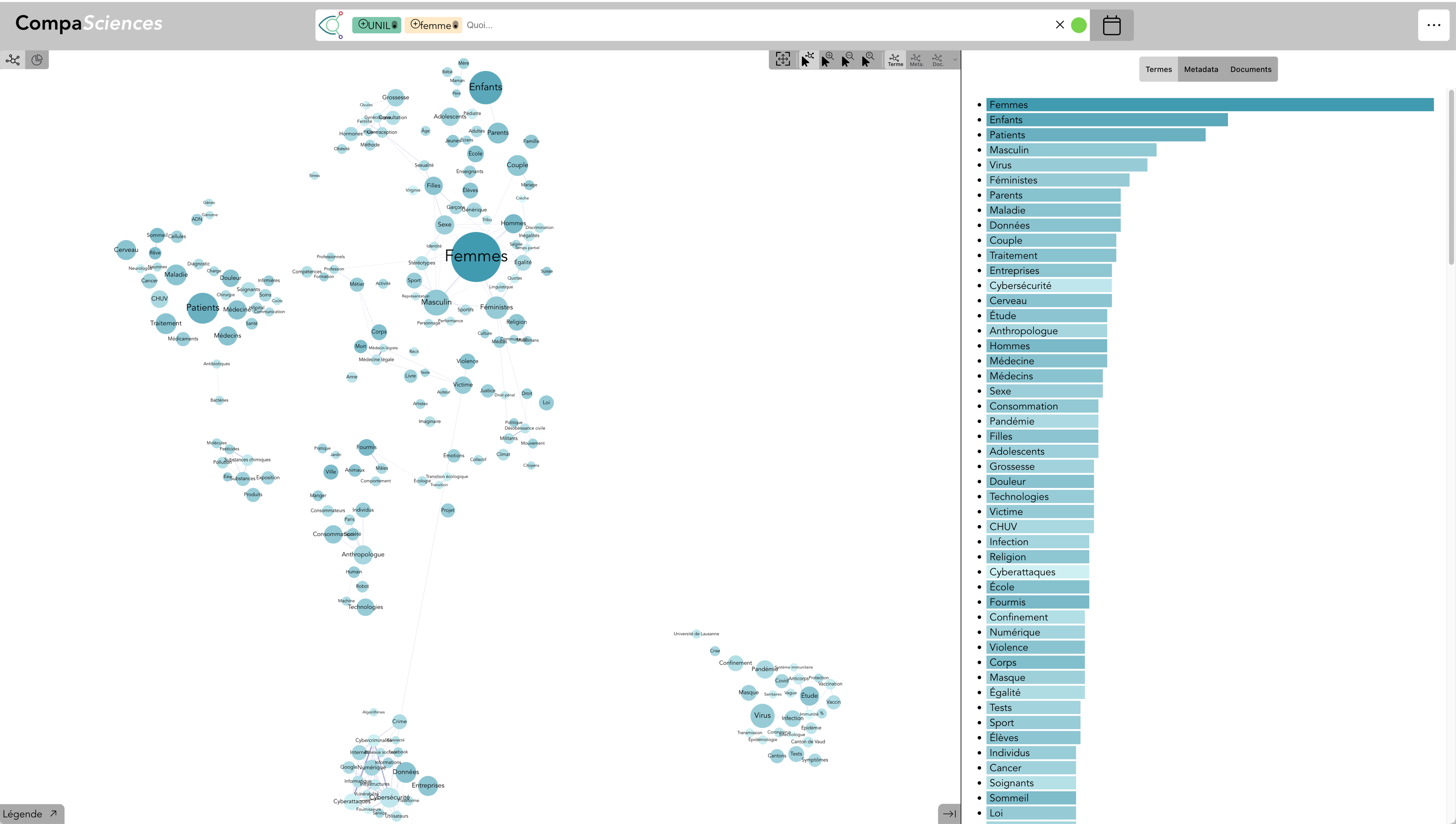
Terme : Durabilité & Institution : UNIL & Genre : Femme - avec Expert·e·s (live)
En ajoutant le genre Femme, seules les expertes de l’UNIL sont représentées
Interface
Recherche
Limiter la recherche (période)
Permet de restreindre la recherche à une période.
Remplacer la recherche
Remplace la recherche par un terme de l’environnement sémantique.
Ajouter un terme
Ajoute directement un terme à la recherche depuis le réseau sémantique.
Supprimer un terme
Supprime directement un terme de la recherche depuis le réseau sémantique.
Vues
Vue du réseau sémantique
Lorsque le compte y est autorisé, permet de passer du Dashboard au réseau sémantique.
Vue du Dashboard
Lorsque le compte y est autorisé, permet de passer du réseau sémantique au Dashboard.
Légende
Ouvre la légende.
Fermeture du panel
Ferme le panneau d’information.
Recadrage automatique
Permet de recadrer automatiquement le réseau sémantique à la taille de l’écran.
Focus sur un terme
Souligne les termes reliés à un terme spécifique du graphe et positionne la liste des termes sur ce terme.
Spatialise les termes
Positionne les termes selon leur proximité sémantique.
Spatialise les documents
Positionne les documents selon leur proximité sémantique.
Spatialise les métadonnées
Positionne dans le réseau de termes la métadonnée sélectionnée dans le panel. Privilégie la relation entre les termes et les experts. La relation entre les termes est donc moins fiable.
Réglages
Permet d’accéder au compte de connexion et aux différents réglages plus avancés
-
Identifiant de connexion et déconnexion
-
Langue de l’interface (français et anglais)
-
Paramètres avancés
-
Paramètres visuels
-
Paramètres de placement des nœuds
-
Paramètres de placement des métadonnées
-
Réexcution de la spatialisation (pour celles qui ont une composante aléatoire, telle que UMAP).
-
Choix de l’algorithme de spatialisation (UMAP, ForceAtlas2 et MDS)
Panel
Termes
Présente la liste des termes les plus pertinents pour les critères de recherche (cf. Recherche).
La pertinence correspond à l’association spécifique des termes et non à leur occurrence. Des termes très occurrents, mais peu spécifiques à cette recherche seront donc moins bien classés que des termes moins occurrents, mais spécifiques à cette recherche.
-
La pertinence est représentée par la barre horizontale.
-
L’occurrence est représentée par l’intensité
Pour chaque terme, il est possible d’approfondir la recherche ou de disposer d’informations complémentaires
Page Wikipédia pour ce terme
Ajoute cet expert à la recherche
Ajoute cet expert à la recherche
Ajoute cet expert à la recherche
Ajoute cet expert à la recherche
Présente le nombre de sujets avec ce terme pour la recherche considérée, le nombre d’occurrences et le score de pertinence pour ce terme (sur 100).
Liste des termes équivalents
Présente la liste des termes équivalents ainsi que leurs occurrences pour la recherche considérée. Le terme le plus occurrent est présenté comme terme de référence dans la liste et dans le réseau.
Lien vers la page Wikipédia du terme
Expert·e·s
Présente la liste des experts les plus pertinents pour les critères de recherche (cf. Recherche).
Les experts peuvent être identifiés selon deux approches : leur présence ou leur spécialité.
-
Présence : les experts sont classés selon leur présence dans les médias pour une recherche particulière (somme de leurs proximités avec le réseau sémantique).
-
Spécialisation : les experts sont classés selon leur spécialisation dans les médias pour une recherche particulière (moyenne de leur proximité avec le réseau sémantique).
Détails
Pour chaque expert·e·s, il est possible d’approfondir la recherche et de disposer d’informations institutionnelles.
Ajoute cette métadonnée à la recherche
Remplace la recherche par cette métadonnée
Recherche cette métadonnée sur Google
Sujets
Présente la liste des sujets les plus pertinents pour les critères de recherche (cf. Recherche).
Les sujets peuvent être organisés selon quatre logiques : détails, groupes, tri et ordre de tri.
-
Détail
-
Compact : seul le titre des émissions est affiché
-
Détaillé : les métadonnées relatives aux sujets sont affichées (émission, experts, institutions et domaine.
-
-
Groupe
-
Sans : les sujets ne sont pas regroupés
-
Date : les sujets sont regroupés par date
-
Mois : les sujets sont regroupés par mois
-
Émission : les sujets sont regroupés par émission
-
Genre : les sujets sont regroupés par genre
-
Institutions : les sujets sont regroupés par mois
-
Section : les sujets sont regroupés par section
-
-
Tri
-
Pertinence : les sujets sont triés selon leur proximité avec le réseau sémantique.
-
Date : les sujets sont triés par date
-
-
Ordre
-
Décroissant : les sujets sont triés dans l’ordre décroissant selon la méthode de tri choisie (pertinence ou date).
-
Croissant : les sujets sont triés dans l’ordre croissant selon la méthode de tri choisie (pertinence ou date).
-
Dashboard
Le Dashboard permet d’explorer le corpus selon ses métadonnées (personnes, émission, genre, institution, domaine), en considérant les documents retenus pour une recherche particulière.
Pour chaque métadonnée, le Dashboard présente le nombre de documents observés et le nombre de documents attendu (si la recherche était représentative de l’ensemble du corpus). Par exemple, une institution ou une émission qui rassemble beaucoup de documents dans l’ensemble du corpus peut être très présente dans les résultats, même si elle traite relativement peu du sujet. Cet indicateur permet de faire la différence entre sa présence absolue (nombre de documents observés) et relative (nombre de documents attendus). Cette précision est par exemple très pertinente pour le genre, les femmes étant globalement beaucoup moins représentées dans les médias. Elles peuvent en cela être minoritaires sur un sujet, tout en l’abordant bien plus qu’attendu au regard de leur présence dans l’ensemble du corpus (voir l’exemple infra sur les adolescents).
Exemple pour une recherche sur les adolescents (explications)
Dans cet exemple, on voit par exemple que :
-
Le CHUV est l’institution la plus représentée (plus de 90 interventions dans les médias), mais qu’elle est aussi beaucoup plus présente sur le sujet qu’attendue, au regard de sa présence dans l’ensemble du corpus (un peu moins de 40 sujets étaient attendus). Inversement, l'UNIGE, très présente aussi (52 sujets), est pourtant beaucoup moins présente qu’attendu au regard de sa présence dans l’ensemble du corpus (94 sujets). Le CHUV est donc non seulement l’institution qui intervient le plus sur le sujet, mais aussi la plus spécialisée dans le domaine.
-
Les hommes sont ceux qui interviennent le plus sur le sujet (97 sujets contre 94 pour les femmes), mais il apparaît qu’ils interviennent pourtant moins sur le sujet que ce que nous pourrions attendre au regard de leur présence dans l’ensemble du corpus (144 sujets, contre 49 pour les femmes). Les femmes interviennent en cela légèrement moins que les hommes sur le sujet, mais beaucoup plus qu’attendu si l’on considère l’ensemble de leurs interventions dans le corpus. Elles parlent donc bien plus des adolescents que ne le font les hommes, en général.
-
La surreprésentation des femmes sur le sujet est aussi clairement perceptible lorsque l’on considère les personnes qui interviennent. Anne Edan (service de psychiatrie de l'enfant et l’adolescent des HUG) est non seulement la personne qui intervient le plus, mais elle intervient de surcroît beaucoup plus sur le sujet qu’attendu si l’on considère l’ensemble de ses interventions (17 interventions, alors que 5 seraient attendus). Inversement, Raphaël Heinzer (pneumologue au CHUV) intervient beaucoup sur le sujet (12 interventions), mais bien moins qu’attendu au regard de sa présence dans l’ensemble des interventions à la RTS (19 seraient attendus sur le sujet).
La méthode pour établir cette représentativité est simple. Prenons une métadonnée (par exemple, une personne, une institution, ou une émission) : sa présence dans le corpus correspond à un pourcentage du total des interventions, disons 1,2%. Si cette métadonnée traitait un sujet de manière neutre, elle serait présente dans la même proportion pour ce sujet particulier. Par exemple, pour 356 interventions concernant les adolescents, on s’attendrait à ce que 1,2% de ces interventions, soit 4,3 interventions, concernent cette métadonnée. Cette approche permet de comparer le nombre d’interventions effectives avec le nombre attendu si la répartition était similaire à celle de l’ensemble du corpus.
Généralisation à d’autres corpus
Le concept de CompaSciences peut être étendu à d’autres corpus de données. À partir des données et des métadonnées fournies, CompaSciences génère automatiquement un environnement d’exploration interactif, intégrant le vocabulaire, les métadonnées et les documents associés. La recherche, avec suggestion automatique, devient immédiatement opérationnelle.
Cette approche a été testée sur divers corpus, tels que l’intégralité du journal Le Temps ainsi que les versions francophone et anglophone de Wikipédia. Pour la médiation scientifique, une version complémentaire à celle dédiée aux interventions médiatiques exploite la base de données Recherche de projets du Fonds national suisse (FNS).
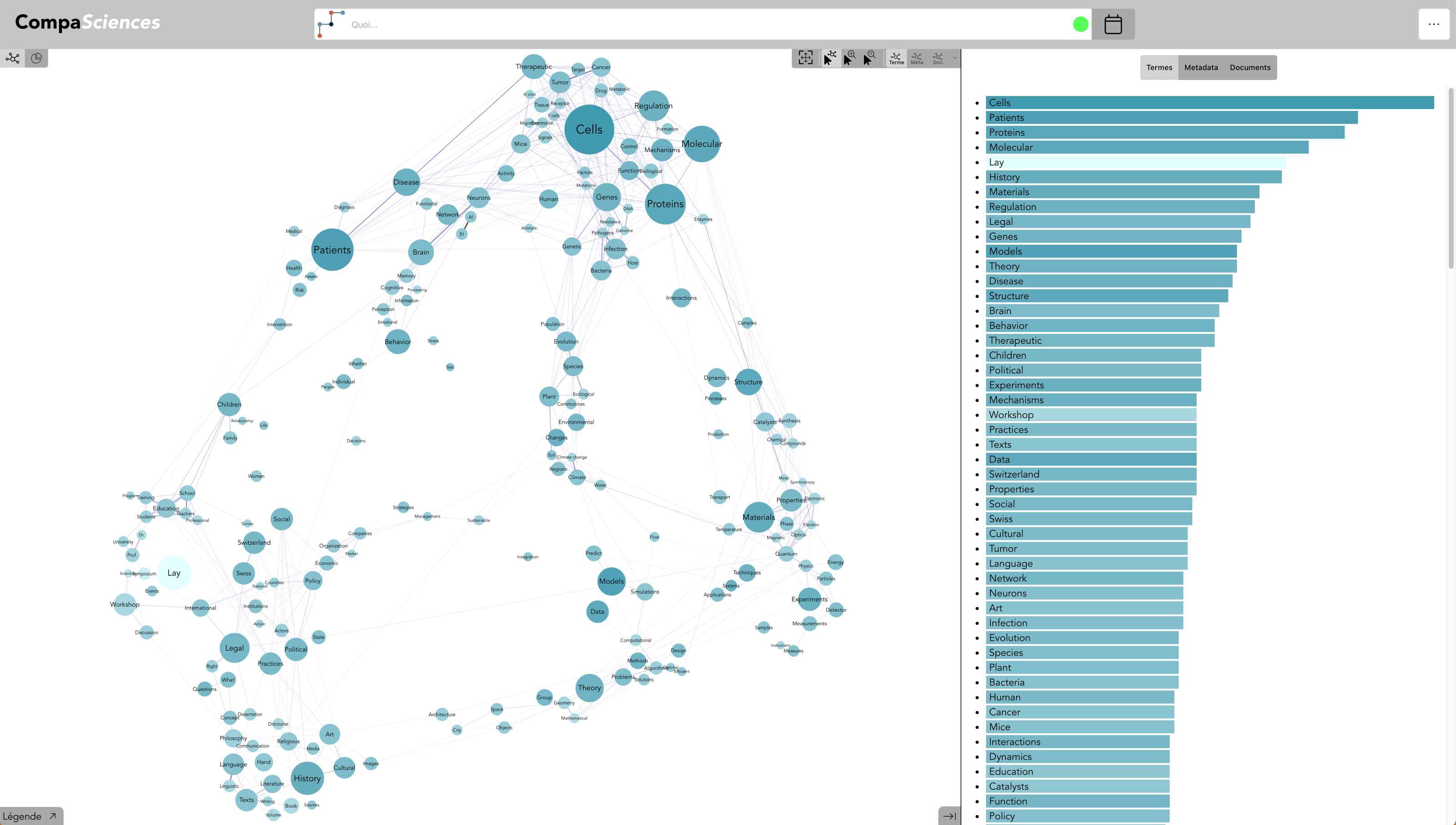
Accueil de la version FNS (live)
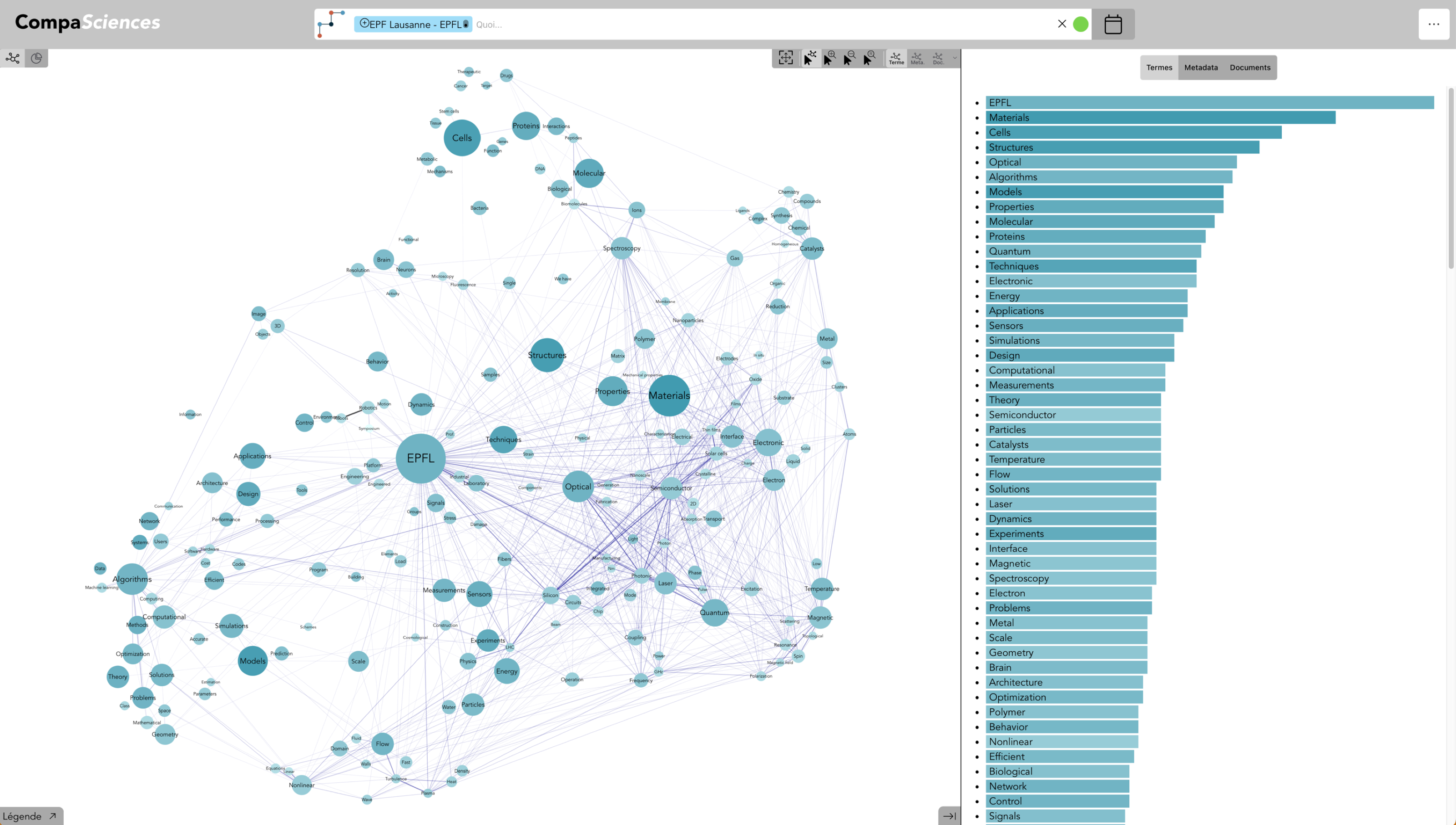
Institution : EPFL
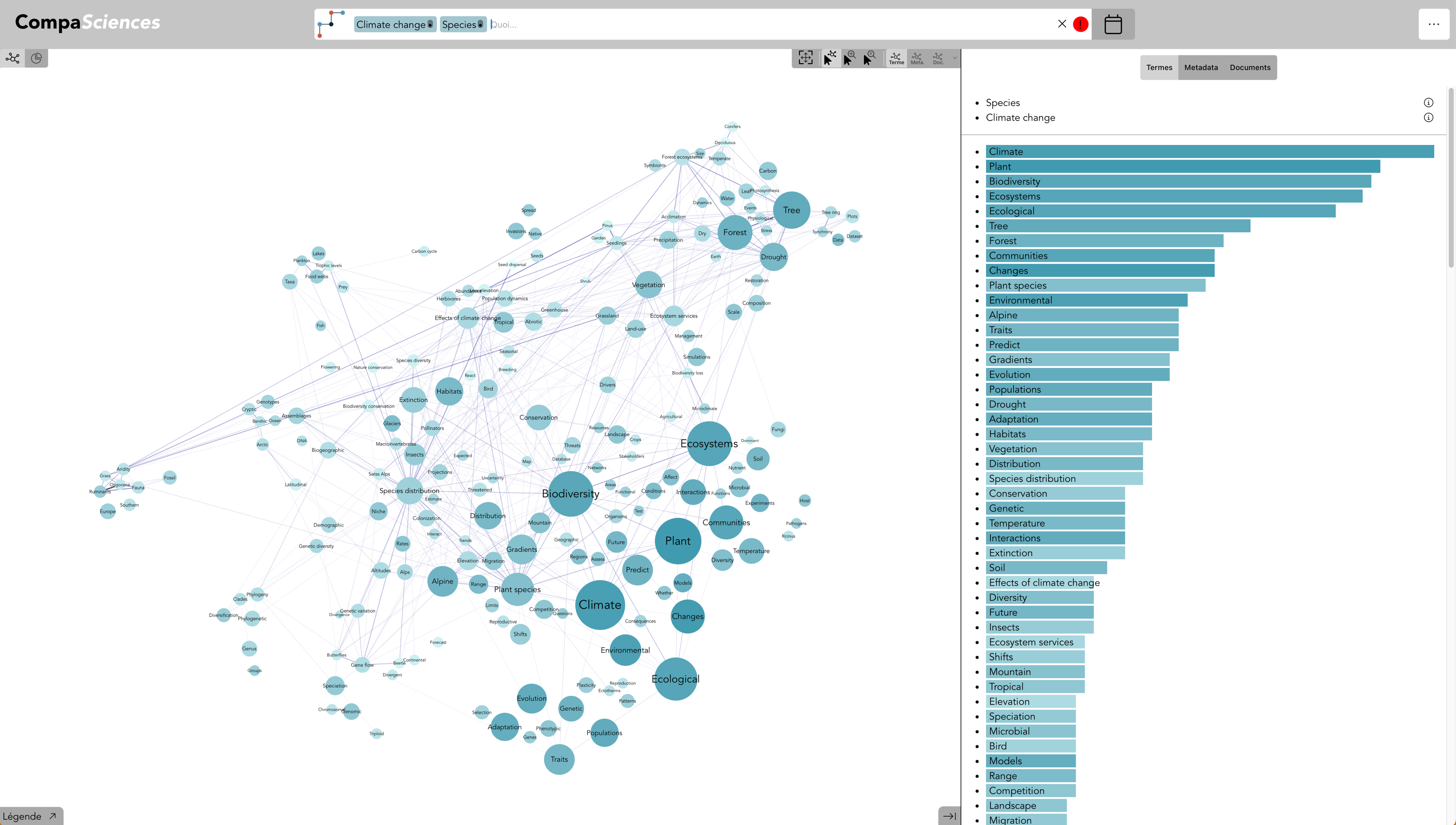
Term : climate change + Term : spacies
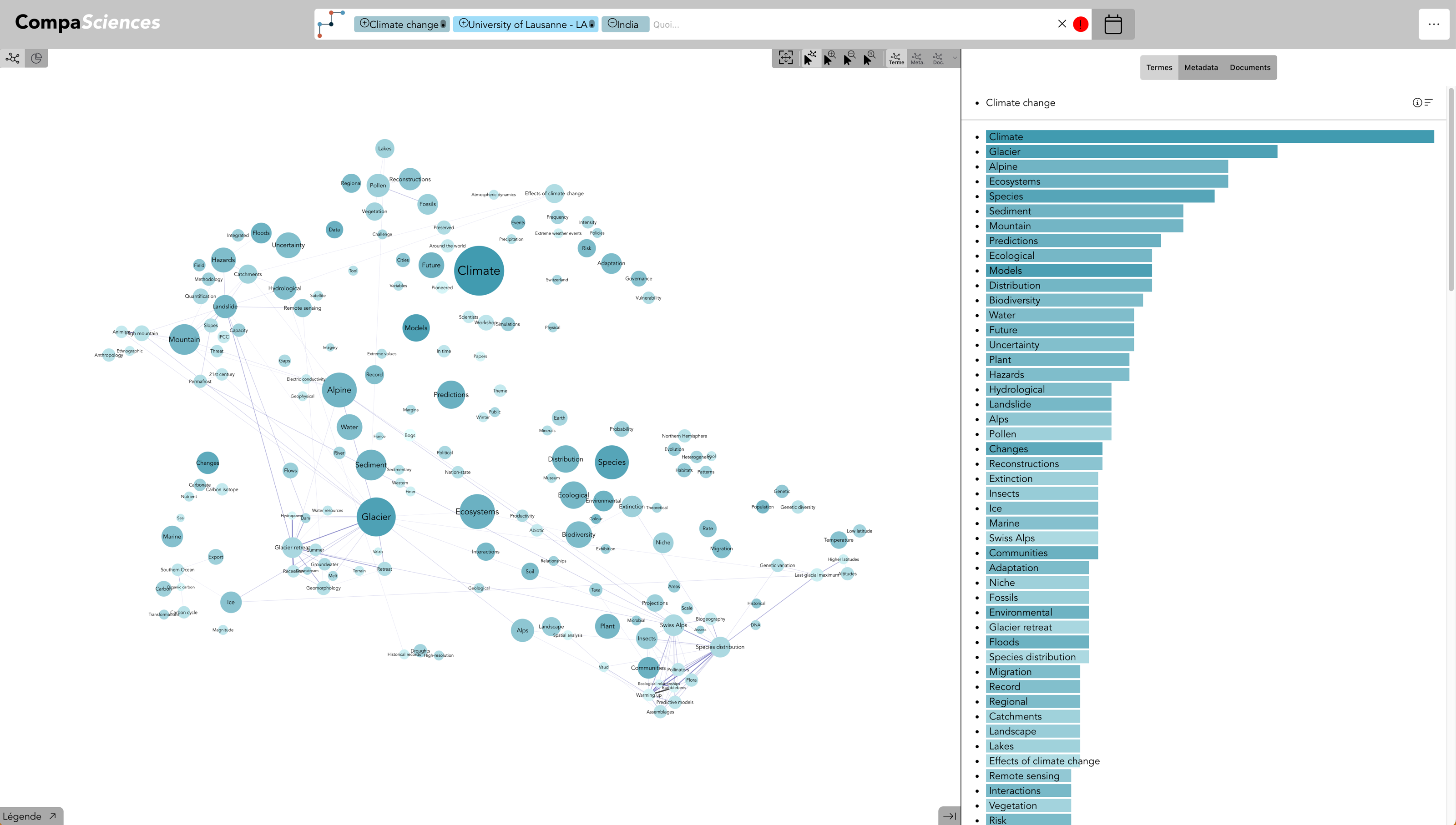
Term : Climate change + Institution : UNIL - Term : India
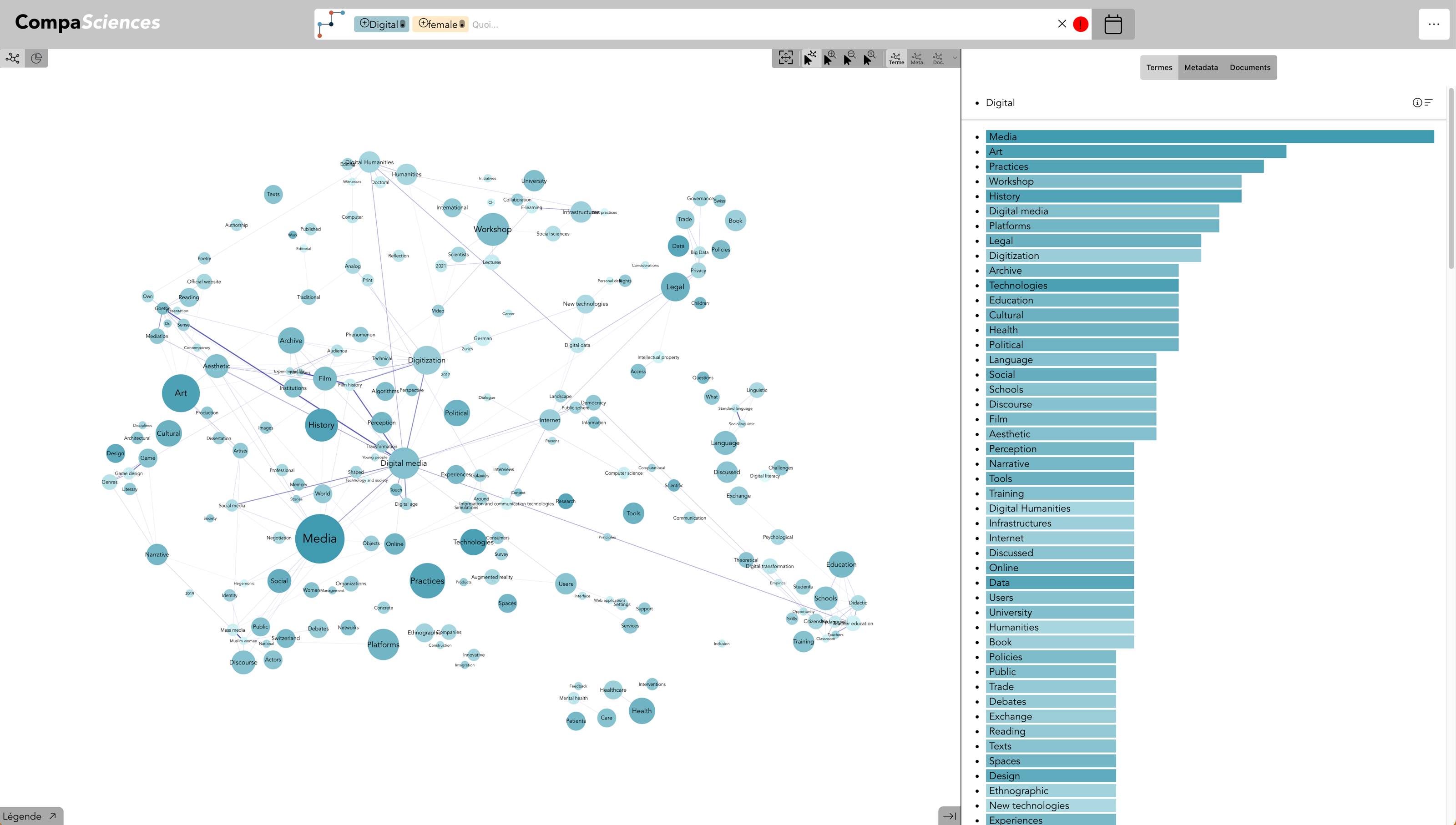
Term : digital + Gender : female
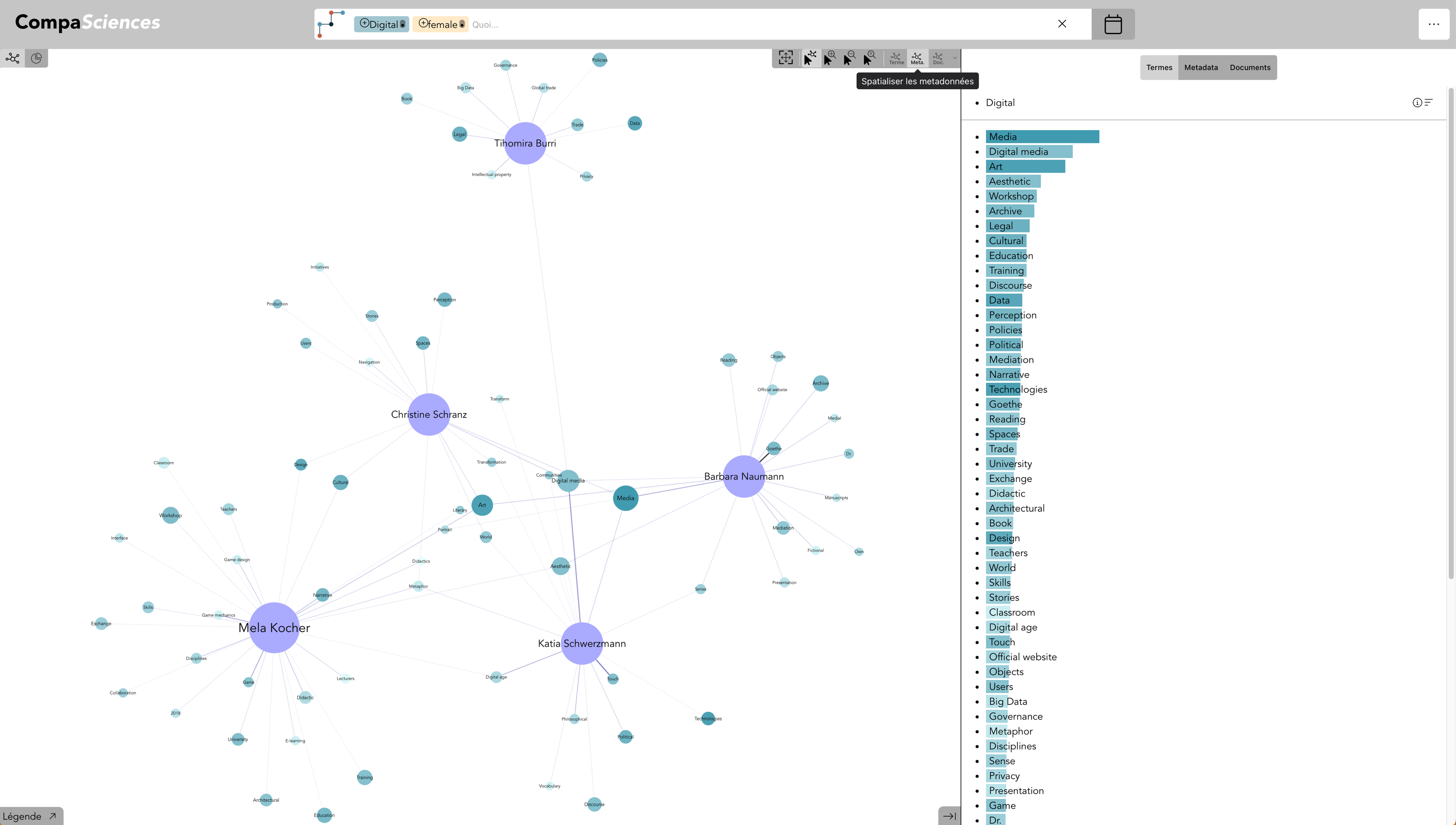
Term : digital + Gender : female & Display meta : Expert
Recherche de projets du FNS
La version FNS de CompaSciences se distingue par l’utilisation d’une base de données multilingue et par la possibilité de tester l’interface dans une autre langue. La base Recherche de projets recense tous les projets financés par le FNS. Elle contient des informations (titre, résumé, description, etc.) disponibles en français, allemand, italien ou anglais. Toutes ces données ont ensuite été automatiquement traduites en anglais.
Cette version de CompaSciences repose donc sur un vocabulaire complètement différent, aussi bien sur le plan thématique que linguistique. Elle démontre la capacité de CompaSciences à s’adapter à des corpus de langues et de domaines différents.
Équipe de recherche
CompaSciences est un projet de recherche qui a été financé par l’Initiative for Media Innovation (IMI). Il est à présent soutenu aussi par l’UNIL, afin d’identifier rapidement des expert·e·s de domaines spécialisés. Son équipe est plurielle et rassemble de multiples compétences
Pr. Boris Beaude (UNIL)
Direction du projet
- Conceptualisation du projet
- Analyse et traitement des données
- Interface et communication
Dr. Ogier Maitre (UNIL)
Responsable informatique
- Supervision
- Développement de l'interface
Mathieu Pavageau (UNIL)
Développeur sénior
- Développement de la version de production
- Extraction et structuration des données
Personnes ayant contribué à la version expérimentale du projet
Le pilote de ce projet est associé à une recherche qualitative, en relation étroite avec des journalistes de la RTS. Cette équipe a contribué à la pertinence de CompaSciences. Elle a aussi travaillé étroitement avec le projet Avis d’Experts (AdE).
Agathe Chevalier (AdE)
Responsable d’Avis d’experts et de la coordination du projet (→ AdE)
Philippe Gonzalez (UNIL)
Direction la composante qualitative
- Entretiens avec les journalistes
- Pertinence des environnements sémantiques
Ulrich Fischer (MemoWays)
Coordination et collaboration avec Avis d’experts et la RTS (→ MemoWays).
Marine Kneubühler (UNIL)
Responsable des entretiens et de l’analyse qualitative
Matthieu Devaux (UNIL)
Développeur junior
- Développement du prototype
BY-SA - Boris Beaude - Conditions d’utilisation (API) - contact@compasciences.ch